Analytes#
An analyte in EnviroData is more than just a name.
Depending on the context, defining a single analyte can may require specifying a combination of the following unique properties:
name (as it is stored in envirodata database)
analysis method
submatrix (e.g., dissolved or solid)
unit
unit group
dislay name (as it is shown on the EnviroData UI)
list of analyte aliases, each with their own attributes
The amount of information that EnviroData needs when determining an analyte depends on the action being performed. For example, when ingesting a datapoint from an EDD, EnviroData either assigns an existing analyte or creates a new one based upon the values of the datapoint’s analyte name, submatrix, and unit. The flowchart below gives an example of this:
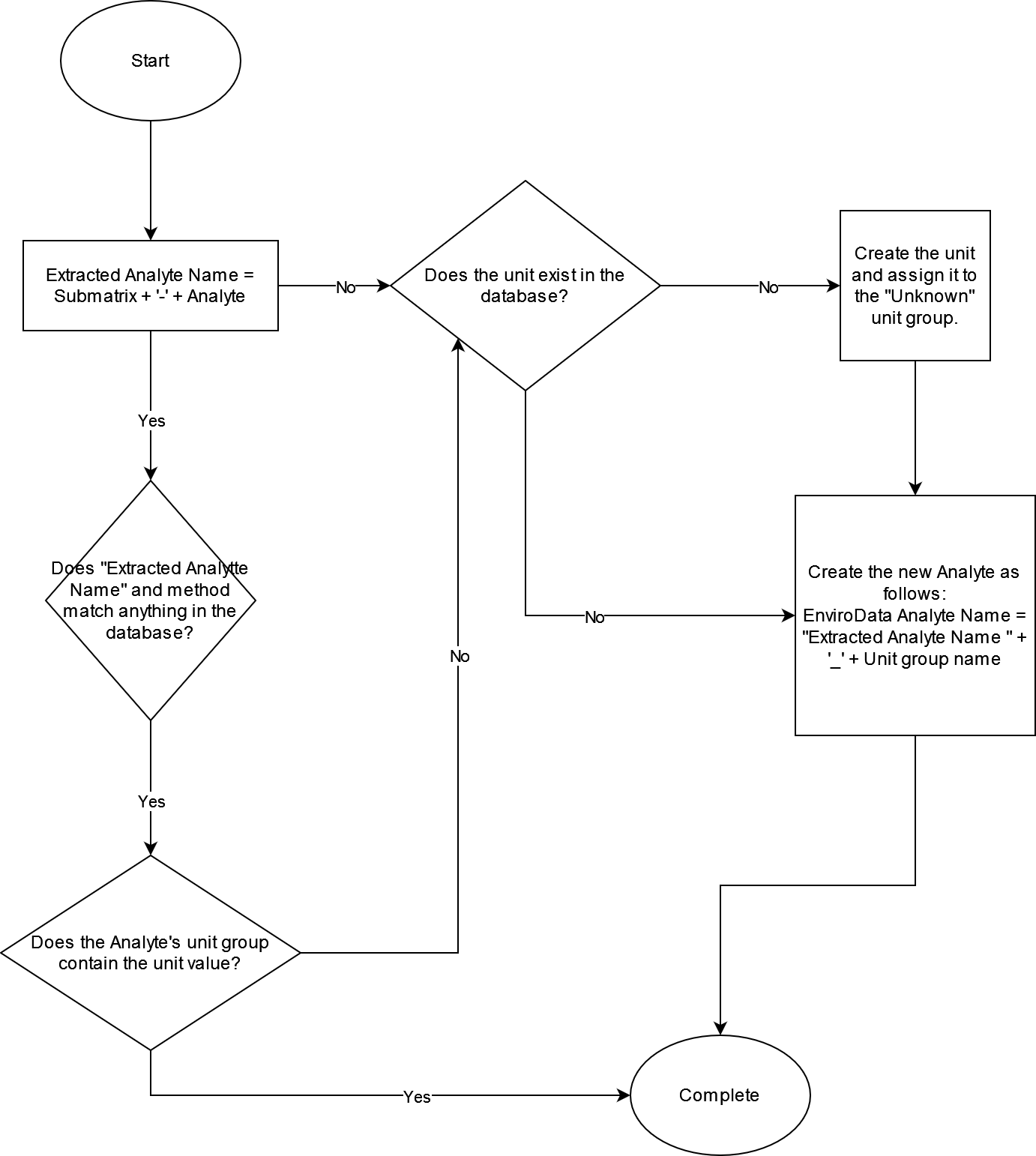
As a concrete example, imagine the following analyte exists in your EnviroData database:
name: Aluminum (Al)
Submatrix: Dissolved
Method: EPA 6020B R2 m
Default Units: mg/L
Unit Group: Concentration (liquid)
Where the Concentration (liquid) Unit group contains the following units:
mg/L
ug/L
ng/L
g/L
Now imagine 4 datapoints of an EDD are ingested, displayed in the image below. How many new analytes will be created?
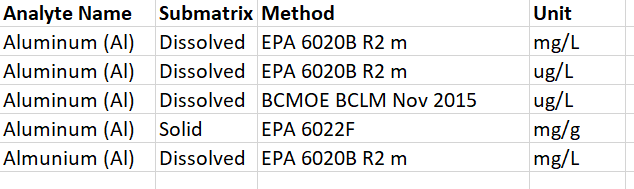
The first two rows will be recognized as existing analytes, since both of their supplied units exist within the Concentration (liquid) unit group. The third row will be saved as a new analyte, since this method+analyte combination does not currently exist in the database. The fourth row will also lead to a new analyte since the analyte name and submatrix combination does not currently exist in the database. Finally, the last row will also be saved as a new analyte. The reason for this is because the Analyte Name was written as “Almunium (Al)” which does not currently exist in the database. Thankfully, EnviroData provides a way of setting analytes as aliases of one another, should there be a typo that you are especially suspectible to making.