Introduction to EcoSurveys#
This introduction will provide you with an overview of EcoSurveys.
What are EcoSurveys?#
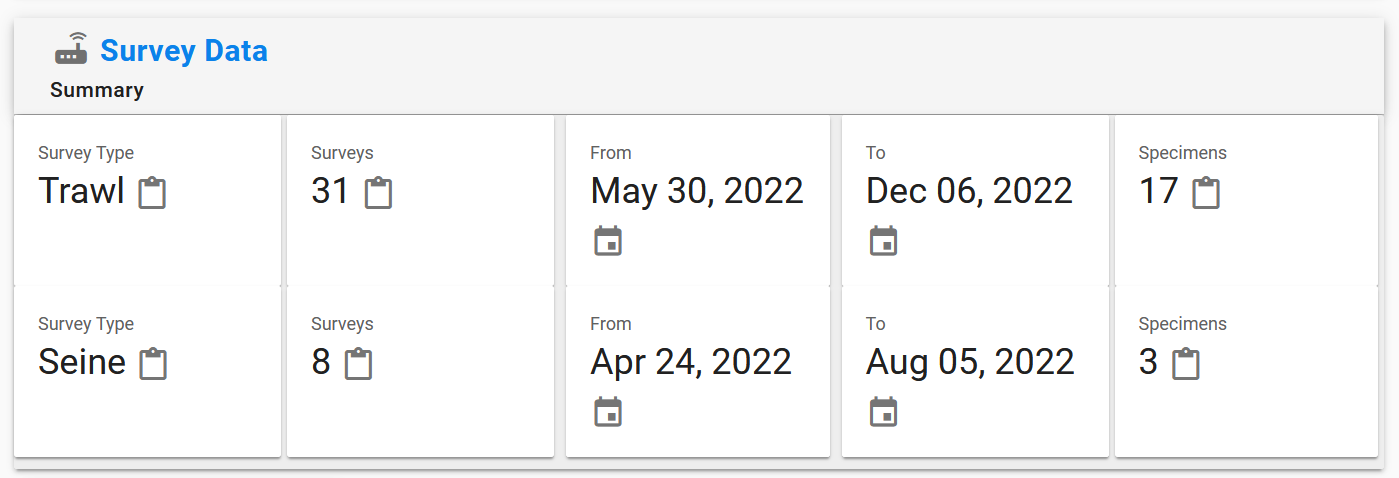
EnviroData EcoSurveys is a new service designed to help users manage their survey data with flexibility and quality control. Using EnviroData’s raw file repository, users can upload their EcoSurvey EDD files and easily ingest survey data. The EcoSurvey EDD format is incredibly versatile and can handle data for any type of observation. EnviroData also keeps track of different survey types based on the observations recorded, ensuring organization and thorough validation for quality control. With EcoSurveys, basic analysis and queries on the dataset can be performed.
EcoSurvey Files#
An EcoSurvey file is a spreadsheet that holds data from an ecological survey. The structure and format of the data in an EcoSurvey file are determined by its schema, which acts as a blueprint of the structure and format of the data that is collected.
In order to ensure data quality and consistency, all EcoSurvey files of the same type must conform to the same schema. Once a schema is set, all data spreadsheets of that EcoSurvey type must conform to the schema, otherwise they will not pass QA/QC validation during ingestion to EnviroData. The schema for a new EcoSurvey type is established upon its initial ingestion based on the column names in the spreadsheet.
Survey Types#
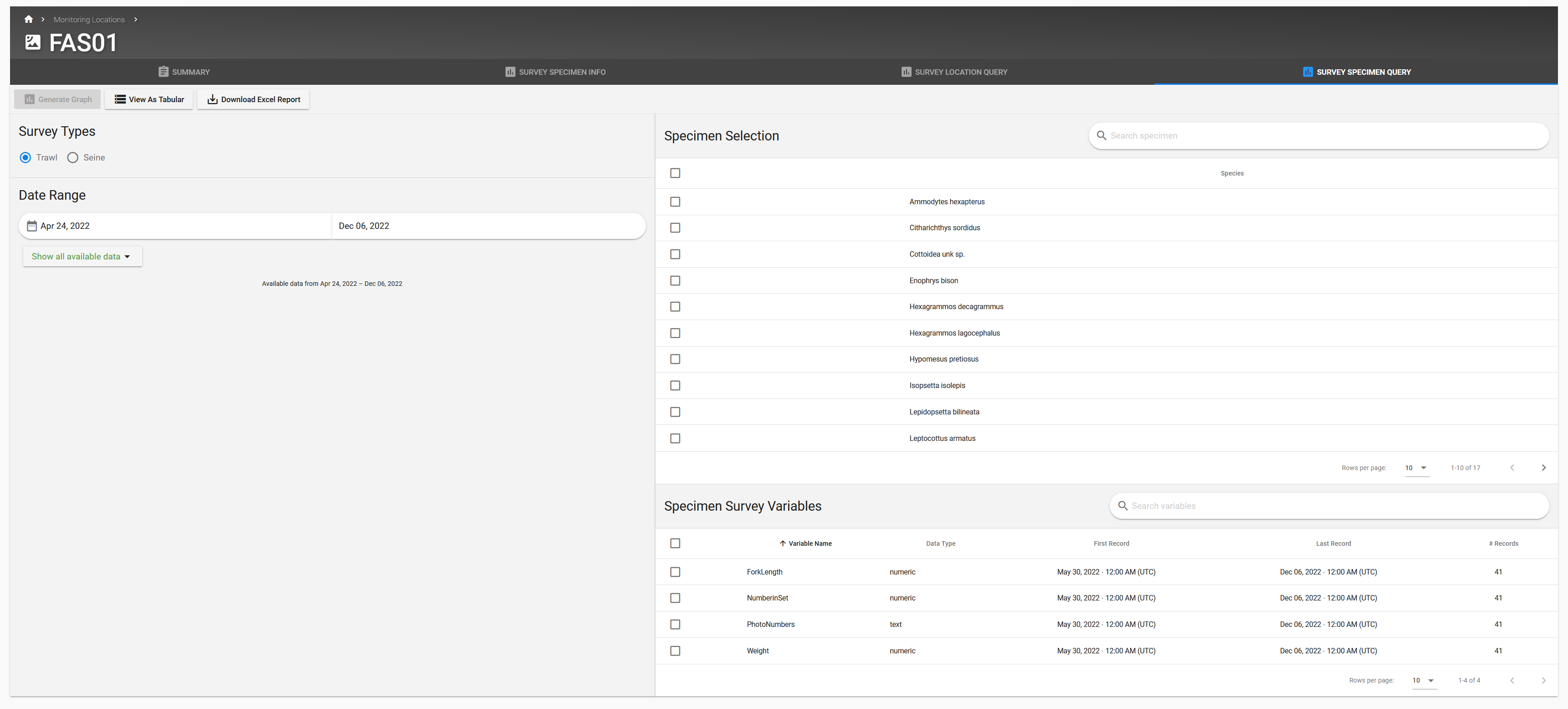
EcoSurveys are organized by survey type. A survey type is defined based on the data contained in the EDD file. Specifically, the values under “SurveyProgramName” and “SurveyType” columns. Survey Program Name is the theme or purpose of a collection of surveys. Survey Type is the name for a specific type of survey, either a high-level taxonomic name or a general idea. The combination of Survey Program Name and Survey Type defines a specific EcoSurvey.
Anatomy of an EcoSurvey File#
An EcoSurvey file has two types of columns: mandatory and dynamic.
Mandatory columns are required for all EcoSurvey files of a particular type and must be present in the spreadsheet. They include SurveyProgramName, SurveyType, SpecimenName, LocationMetadata, and a few others (see the Mandatory EcoSurvey columns section below).
Dynamic columns vary depending on the type of EcoSurvey and the specific data that was collected. These columns are used to store the specific variables and measurements collected in the survey.
When a new EcoSurvey type is ingested for the first time, its schema is established based on the column names in the spreadsheet. Subsequent ingestions of that EcoSurvey type must conform to the established schema, otherwise they will not pass quality assurance/quality control validation.
An EcoSurvey may have multiple specimens, but they should have the same variable data as the other specimens in that survey. If the specimen’s variable data is significantly different, it may be appropriate to separate it into a different SurveyType.
In summary, the anatomy of an EcoSurvey file consists of mandatory columns and dynamic columns, which are determined by its schema. This schema ensures that all EcoSurvey files of the same type have consistent structure and format, allowing for efficient data analysis and interpretation.
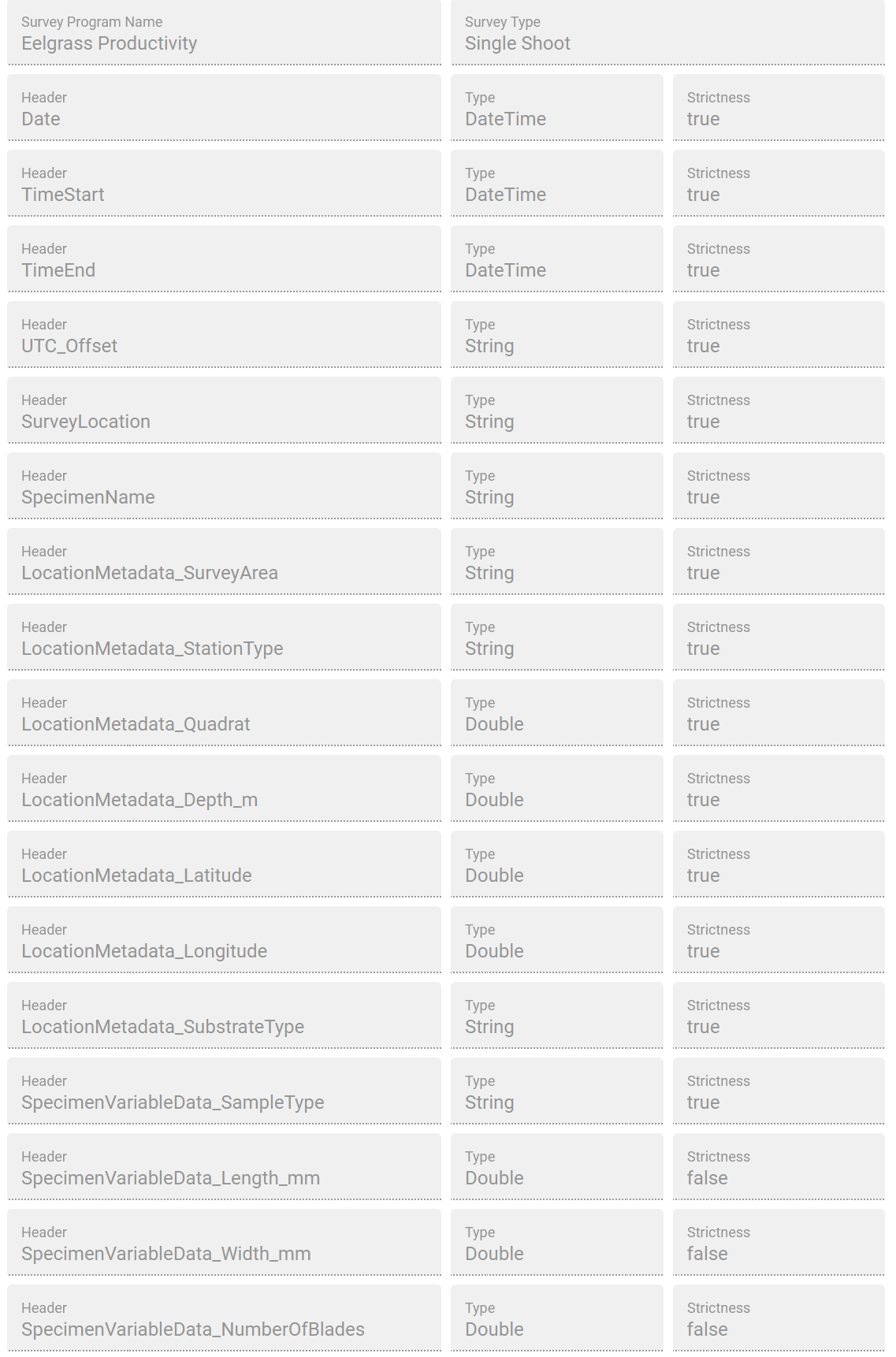
Mandatory EcoSurvey Columns#
The following columns must always be present in a spreadsheet to consider it as an EcoSurvey EDD during validation. If the validation fails, the file will be uploaded to RDR as a Generic file.
SurveyProgramName: The name of the collection of survey types.
SurveyType: The type of survey, could be a taxonomic name or general purpose.
Date: The date of the survey.
TimeStart: The start time of the observation.
TimeEnd: The end time of the observation.
UTC-Offset: The time zone.
SurveyLocation: The name of the survey location.
SpecimenName: The name of the object being observed.
Dynamic Columns#
These columns provide flexibility to the EDD, allowing you to have as many columns as you need. However, each column must have a prefix which must always be present. If not, the column will be considered a Mandatory Column.
LocationMetadata_*: Data about the location of the survey.
SpecimenVariableData_*: Data about the specimen observed.
As mentioned above, a survey type can include as many dynamic columns as you’d like. However, once a survey type is defined, all subsequent ingestions of that survey type must have the same dynamic columns. The required dynamic columns for a survey type are set during the first ingestion of that survey type. In addition, dynamic columns have the following rules: - The dynamic columns must always have one of the prefixes shown above followed by an underscore. - All underscores after the first one are treated as spaces when parsing the variable name from the column name.
Tips for Organizing EcoSurveys#
SurveyType Column#
The SurveyType column represents the type of survey being conducted. It can either be a high-level classification of the object being studied (e.g. “Bird”) or a broad description of the survey’s objective (e.g. “LandUse”).
Stations are currently organized by SurveyType in EnviroData.
It is important to keep in mind that a SurveyType should accurately reflect the nature of the surveys it encompasses. Avoid using overly-vague or overly-specific terms.
Examples of good SurveyTypes:
Bird
LandUse
Examples of bad SurveyTypes:
Animals
Study
Observation
It’s better to use a more specific term that clearly defines the survey’s focus. The SurveyType is used in conjunction with the SurveyProgramName (below) to identify the correct ecosurvey schema for a file.
SurveyProgramName Column#
The SurveyProgramName column refers to the name of a group of survey types.
A good SurveyProgramName should accurately reflect the common theme among all the survey types it includes. This allows for multiple SurveyTypes with different schemas to be included under a single SurveyProgramName, as long as their common theme is captured.
Examples of good and bad SurveyProgramNames:
Example 1
Bad: Impact Assessment
This name provides limited information and does not distinguish between multiple Impact Assessments that may be needed for a project over time.
Better: Playground Construction Impact Assessment
Including a bit more context about the project makes it easier to find the correct survey in the future, when multiple Impact Assessment program surveys may exist.
Example 2
Bad: 2014.
This name only includes a range of dates and does not provide enough information.
Better: 2014 Preliminary Ecological Appraisal
This name provides more context and makes it easier to understand what the survey is about.
Example 3
Bad: Mount Pleasant Birds
While this name may be suitable for some tenants, it may not be appropriate if the tenant is conducting a project to assess the impact of playground construction on various protected species in Mount Pleasant, including birds, rabbits, and squirrels.
Better: Mount Pleasant Protected Species Survey
This name captures the common theme of the surveys and provides more information about the project.
SpecimenName Column#
The SpecimenName column refers to the name of the object being observed. In a survey context, this would be the specific name of the specimen. For example, in a bird survey, this could be “Eagle” or “Crow”. In a fish survey, this could be “Carp” or “Dolphin”. It is important to use a consistent naming convention for SpecimenName, as this will make it easier to organize and analyze the survey data.
The Survey Specimen Query tab of the monitoring location alows users to select a survey type, and then further specify one or more specimens when querying reports.
Examples of SpecimenName:
Bad: Elephant1
Better: African Elephant
“Elephant” is better suited as a SurveyType (depending on the program). Furthermore, using numbers as part of the SpecimenName can make data analysis difficult. See the page on recommended data collection practices for a list of recommendations to streamline your data management.